
|
Mahdi Zaman I am an engineer and researcher, applying my interdisciplinary experience to medical imaging, computer vision, multi-agent intelligence, and communication. I am currently working with Bloom Energy and C3.ai on AI-based optimization of fuel cells. As a researcher, I am affiliated with CAVREL-UCF, College of Engineering and Computer Science. There, I leverage deep learning architectures to develop models for strong visual recognition in medical applications (3D volumetric segmentation, precision surgery) and for collaborative perception in connected agents (3D object detection). Previously, I have also developed protocols for vehicular applications such as tele-operated driving, automated tolling, and dynamic control. I am humbled to get a chance to collaborate with industry researchers from Microsoft, Ford, Honda and Hyundai. If you want to discuss/share ideas to build together, please reach out! My preferred mode of communication is LinkedIn, Email, X. CV / Google Scholar / Github / LinkedIn / Email / X My core curiosity is to explore our abilities as a species, currently exploring vision. I enjoy thinking and working on algorithms and systems aimed at robot vision and learning; at both micro and macro scale. In my spare time, I enjoy learning diverse concepts (current points of interest: evolution, fitness, neuroscience, psychology, spirituality) and experiment on myself; chasing the core of epistemology where it all comes together. I often share my summarized thoughts and personal experiences through my blog. |
Research & ProjectsMy research projects have been wonderful opportunities to learn about medical imaging, robot perception, remote driving (both automated and humandriven), scaling vehicular communication and writing product-oriented systems for specific applications. Currently I am working on the highlighted projects. |
Health Science & Medical AII develop AI-driven models for surgical video analysis and medical image processing, focusing on action recognition, operation outcome prediction, and efficient deep learning architectures for 3D medical imaging. |

|
Mahdi Zaman, Md Mahfuz Al Hasan, Abdul Jawad, Alberto Santamaria-Pang, Ho Hin Lee, Ivan Tarapov, Kyle See, Md Shah Imran, Antika Roy, Yaser Pourmohammadi Fallah, Navid Asadizanjani, Reza Forghani project page / arXiv Developed a novel transformer architecture utilizing frequency domain representation of high-dimensional features for multi-resolution feature extraction. Our model achieves state-of-the-art performance in 3D volumetric segmentation for organ and tumor detection from CT scans and MRI images. |

|
Mahdi Zaman, Md Sanzid Bin Hossain, Dexter Hadley project page Working on an action recognition model for robotic surgery videos to assess procedural steps and predict operation success/failure, leveraging VLM architectures and temporal analysis. |
Perception & Control for Autonomous AgentsWorking on scene understanding / representation learning, for vehicles / warehouse robots / agricultural tractors to make better decisions. |
|
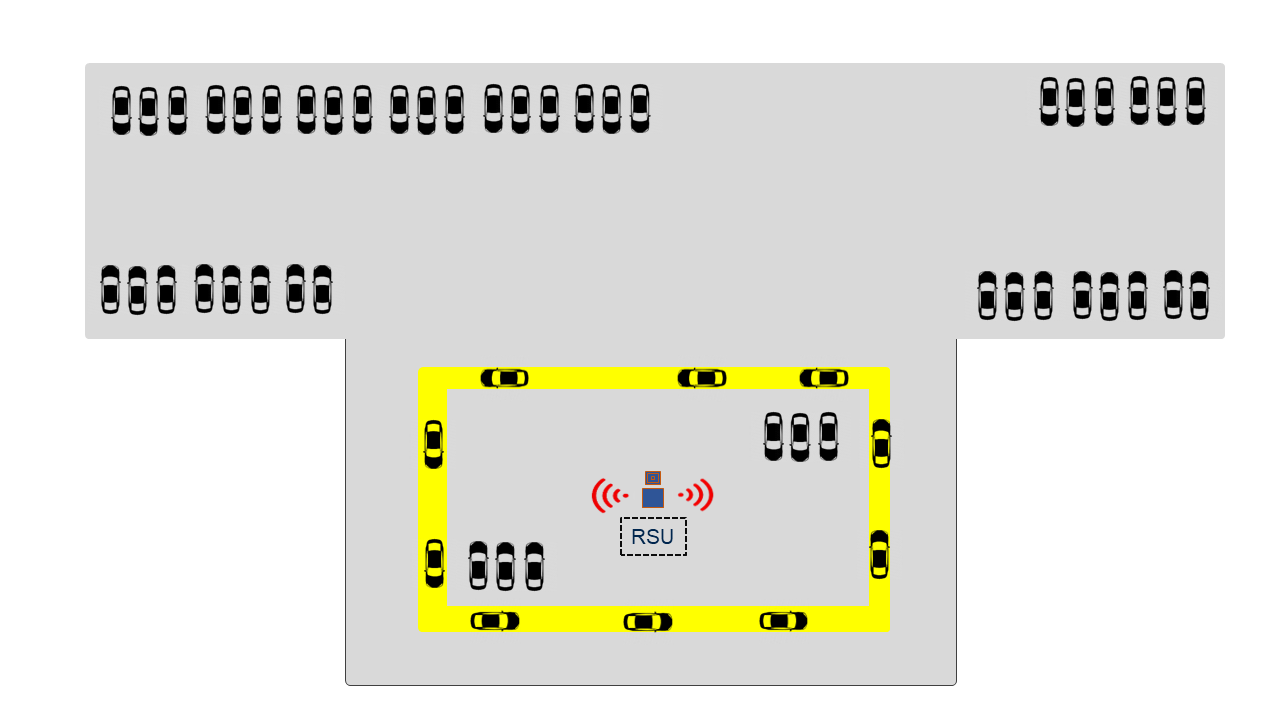
Mahdi Zaman, Ghayoor Shah, Yaser P Fallah project page Enabling remote driving in controlled terrain for manufacturing/warehouse/parking applications with V2X connectivity. We developed novel medium access protocol for no-loss communication in indoor warehouse which proved to be reliable on synthetic scenarios. We're currently scaling for larger vehicle capacity with equivalend bandwidh-efficiency. |

|
Mahdi Zaman, Ghayoor Shah, Yaser P Fallah project page Developed channel-efficient feature generation, sharing and fusion to efficiently leverage visual cues from neighboring agents in a multi-agent setting. Our model is currently being tested on several collaborative perception datasets for proving its generality and scalability. |
|
Rodolfo Valiente, Mahdi Zaman, Yaser P Fallah, Sedat Ozer Handbook of Pattern Recognition and Computer Vision, Chapter 2.10: pp. 365-384, 2020 |
|
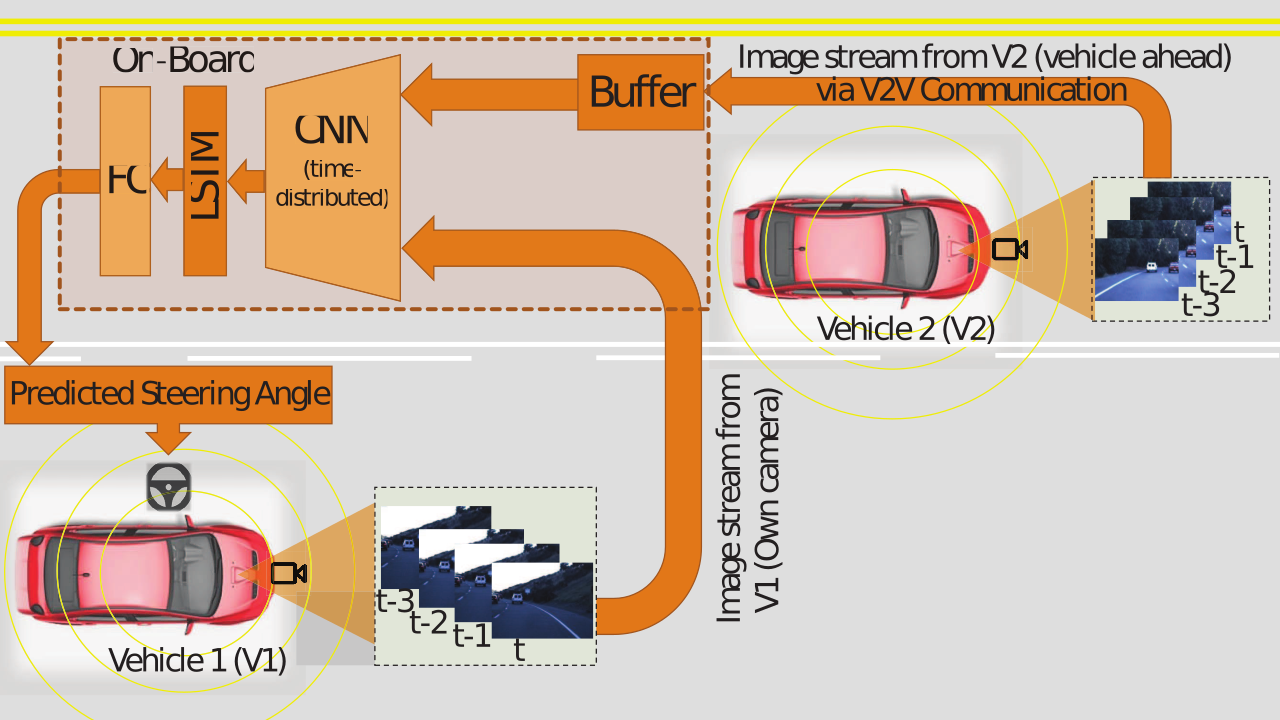
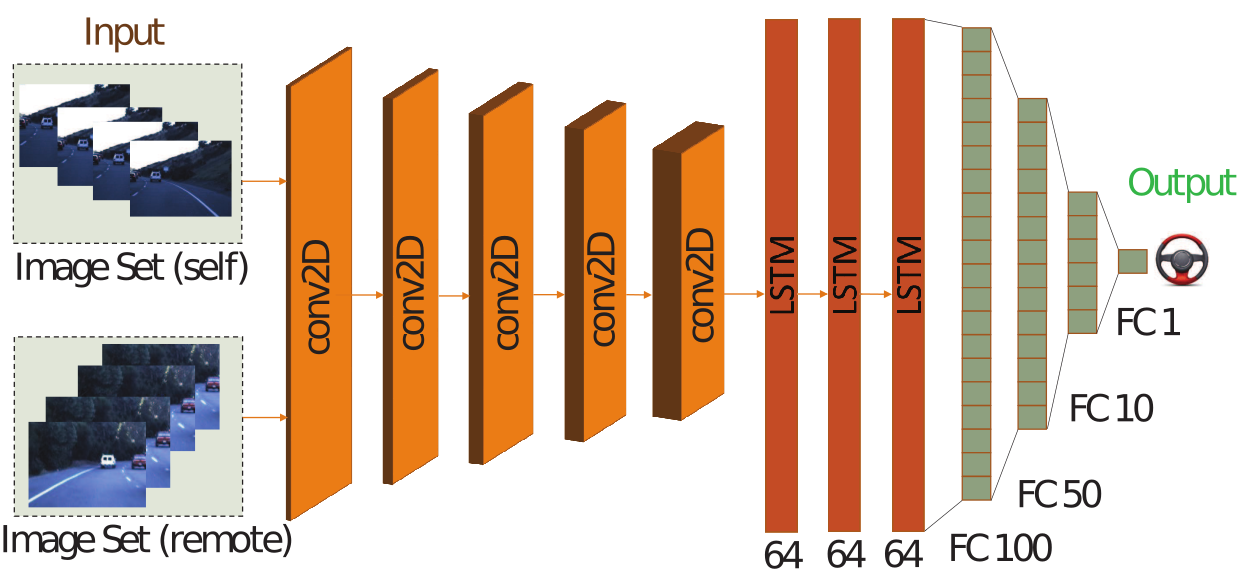
Rodolfo Valiente, Mahdi Zaman, Sedat Ozer, Yaser P Fallah Intelligent Vehicles (IV) Symposium, 2019 paper/ bibtex / poster We present a novel neural network model to leverage local (from on-board sensors) and look-ahead (via V2X) perception for efficient steering maneuver. It empowers the host vehicle with enhanced safety and prior knowledge for navigating a wide range of road scenarios. |
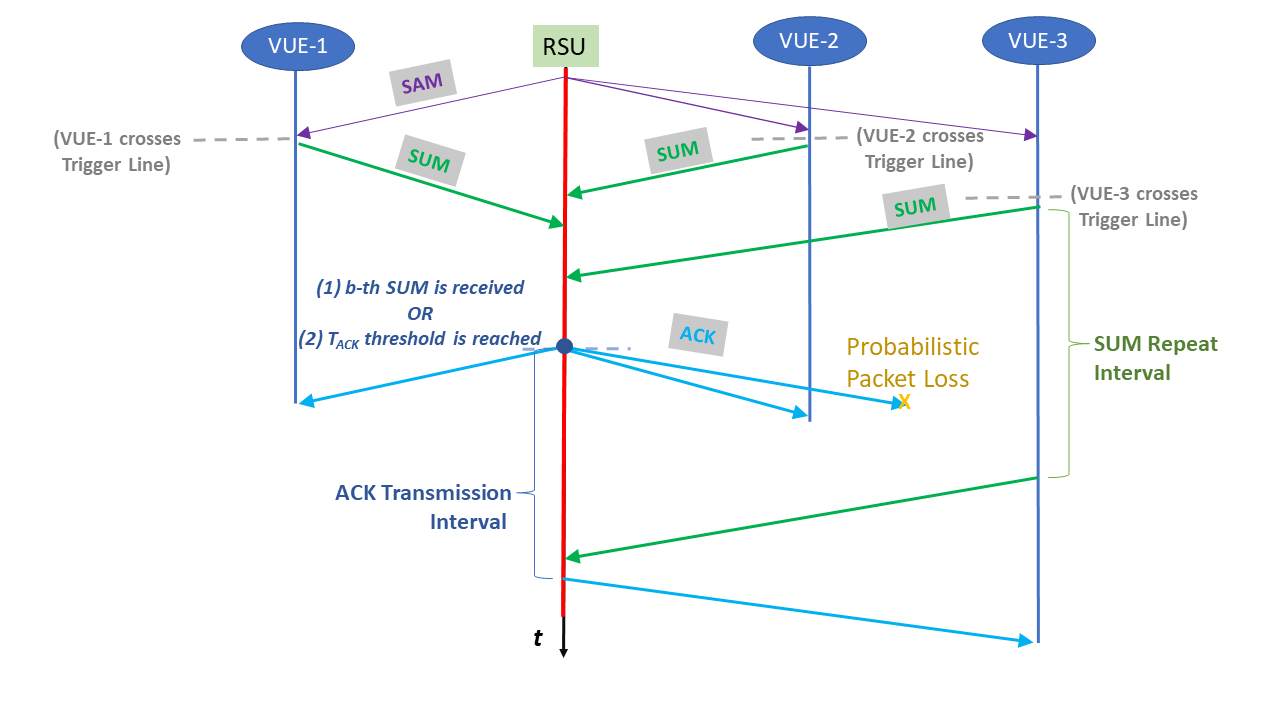
Infrastructure-assisted TollingAn infrastructure-assisted transaction procedure is presented. Potential use-cases are: toll collection, road user charging, remote driving, automated valet parking etc. The application leverages high-speed communication via Cellular-V2X. Outcomes aim for development of SAE J3217 standard. |
|
Mahdi Zaman, Md Saifuddin, Mahdi Razzaghpour, Yaser P Fallah, Jayanthi Rao 97th IEEE Vehicular Technology Conference (VTC), 2023 paper / bibtex |
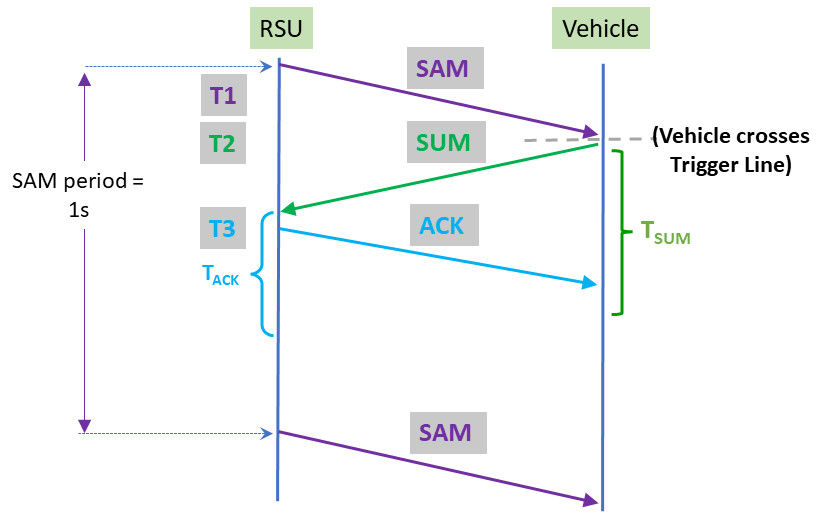
|
Mahdi Zaman, Md Saifuddin, Mahdi Razzaghpour, Yaser P Fallah 96th IEEE Vehicular Technology Conference (VTC), 2022 paper / bibtex / poster |
Scaling V2XVehicle-to-everything (V2X) communication enables vehicles to share their cognition and constitute a form of mass intelligence in partial or fully autonomous traffic environment to overcome the limitations of a single agent planning in a decentralized fashion. Specifically, our proposed methods enable the 3GPP C-V2X communication technology to handle thousands of vehicles in heavily congested environments. |
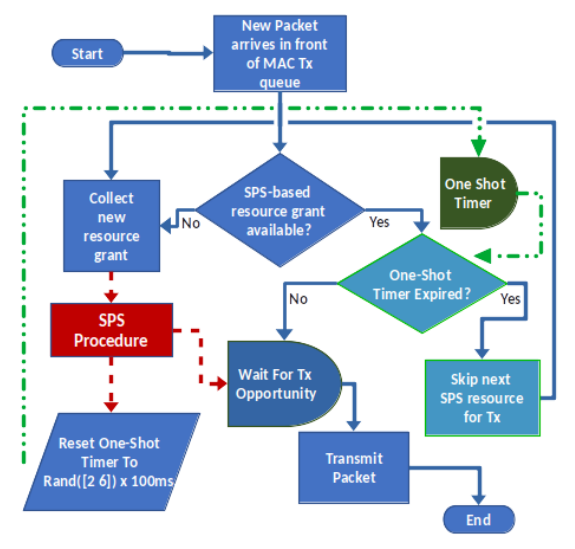
|
Md Saifuddin, Mahdi Zaman, Yaser P Fallah, Jayanthi Rao IEEE TechRxiv, 2023 paper / bibtex |
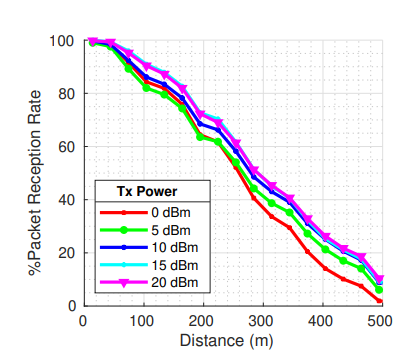
|
Md Saifuddin, Mahdi Zaman, Behrad Toghi, Yaser P Fallah, Jayanthi Rao IEEE Connected and Automated Vehicles Symposium (CAVS), 2020 paper / bibtex |
System Design & Modeling |
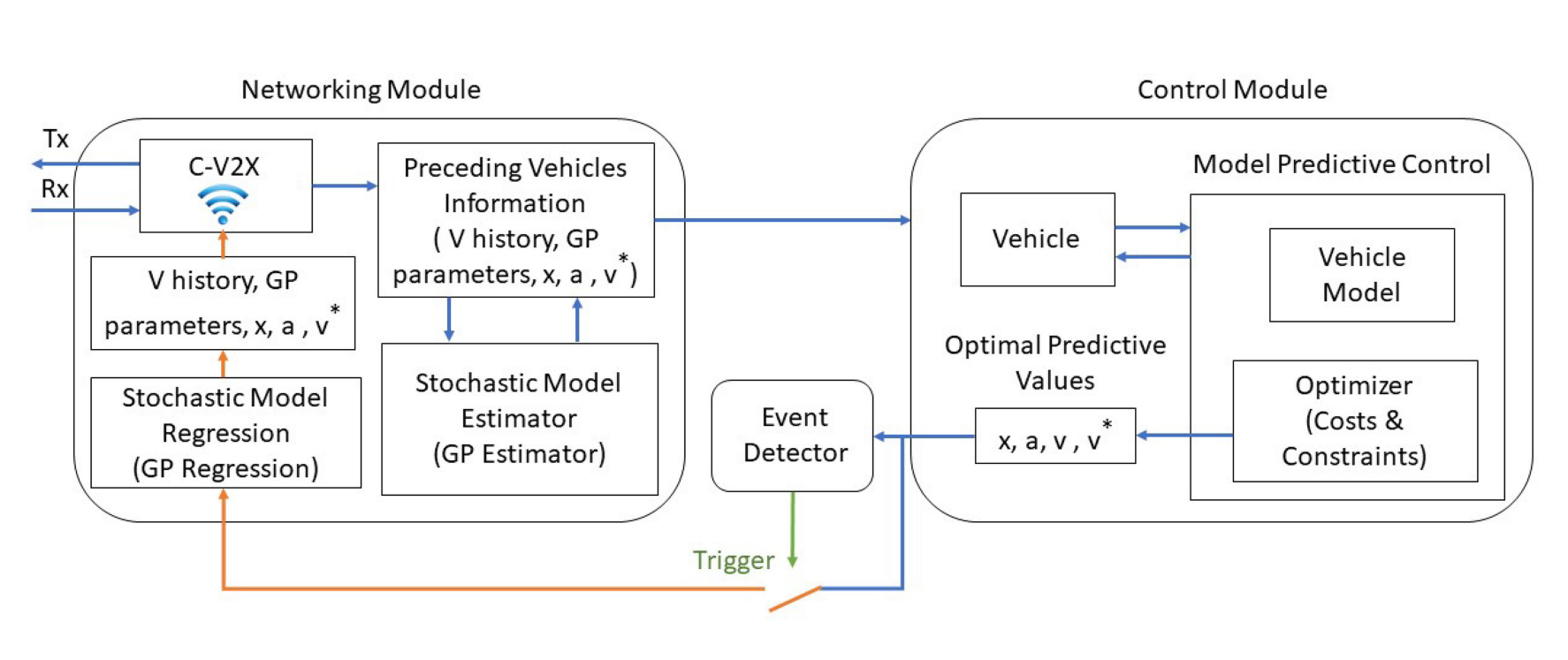
|
Mahdi Razzaghpour, Rodolfo Valiente, Mahdi Zaman, Yaser P Fallah IEEE Open Journal of Intelligent Transportation Systems, Vol. 4, pg 232-243, 2023 paper / arXiv / bibtex We leverage Model-Based Communication (MBC) and propose a solution that enables cooperative control of vehicle platoons under non-ideal communication scenarios. |
|
Mahdi Razzaghpour, Adwait Datar, Daniel Schneider, Mahdi Zaman, Herbert Werner, Hannes Frey, Javad Mohammadpour Velni, Yaser P Fallah IEEE International Systems Conference (SysCon), 2022 paper / arXiv / bibtex We model the inter-vehicle links in a platoon with a first-order Markov model to capture the prevalent temporal correlations for each link. |
|
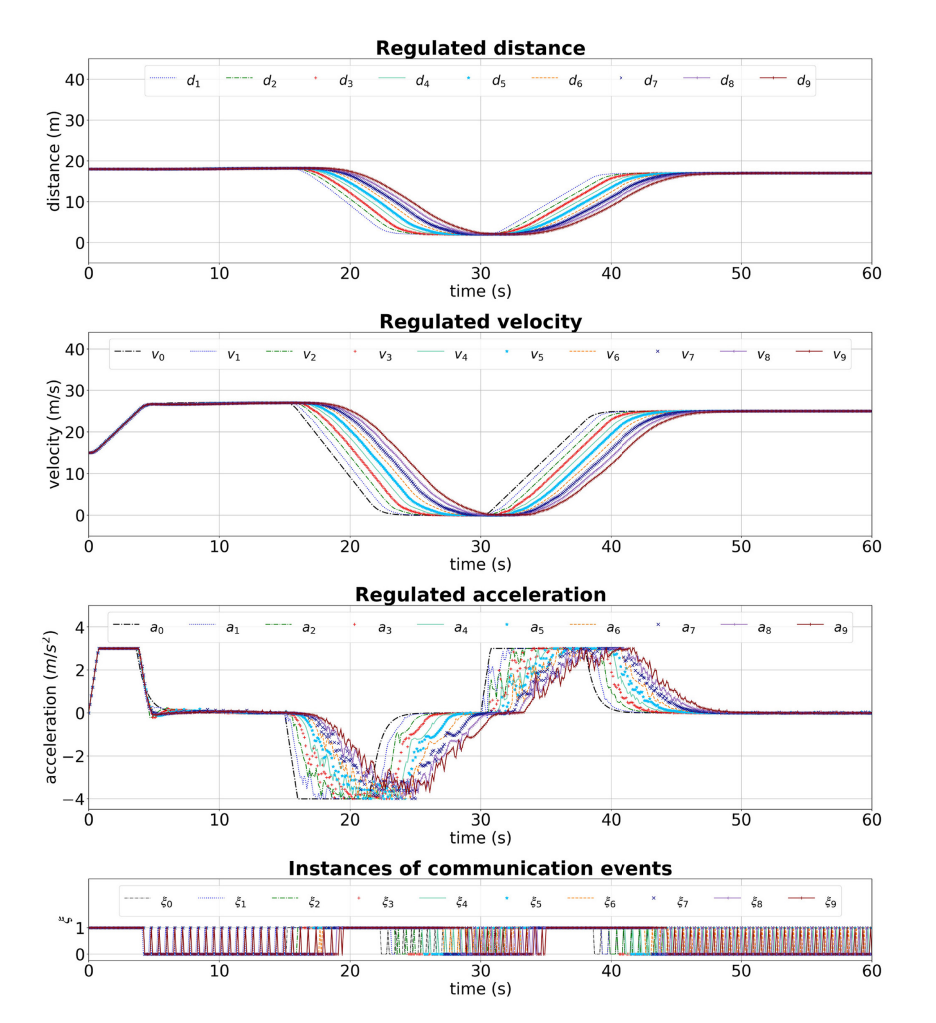
Mahdi Razzaghpour, Rodolfo Valiente, Mahdi Zaman, Yaser P Fallah arXiv / bibtex We propose a combination of control-aware communication and model-based communication. Our proposed solution reduces communication overhead by ~47% while maintaining nearly the same level of efficiency (less than 1% speed deviation) in cooperative adaptive cruise control. |
|
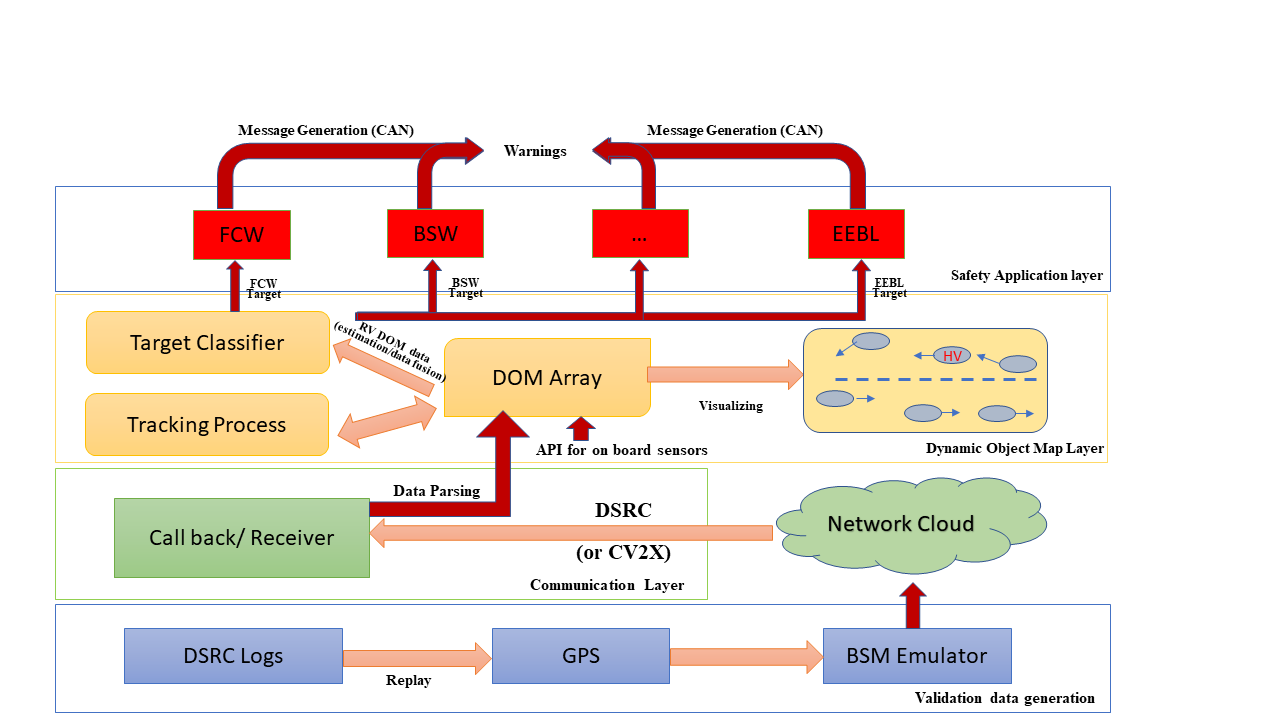
Rodolfo Valiente, Arash Raftari, Mahdi Zaman, Yaser P Fallah, Syed Mahmud SAE Technical Paper, 2020 SAE Mobilus / bibtex We propose a modular architecture with separate subsystems for application and perception with a novel non-parametric Bayesian inference-based prediction method. We validate the architecture in conjunction with the prediction mechanism with real environment using Denso On-Board-Unit (OBU). The proposed system shows enhanced immunity to communication loss in V2X channel. |
|
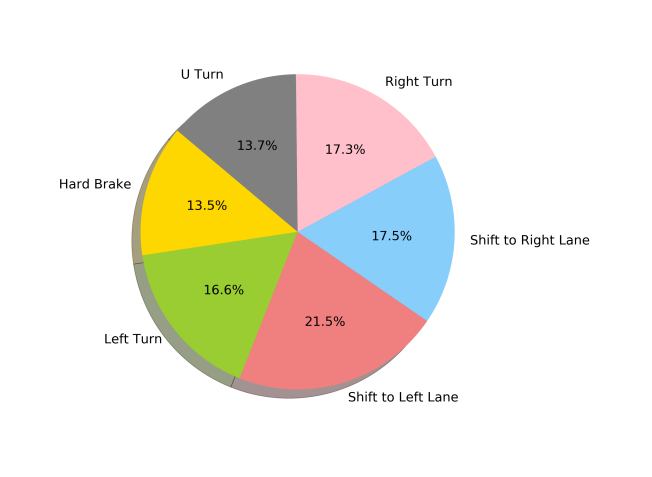
Behrad Toghi, Divas Grover, Mahdi Razzaghpour, Rajat Jain, Rodolfo Valiente, Mahdi Zaman, Ghayoor Shah, Yaser P Fallah IEEE Connected and Automated Vehicles Symposium (CAVS), 2020 paper / arXiv / bibtex We introduce a real-world maneuver-based driving dataset that is collected during our urban driving data collection campaign. |
Patent |
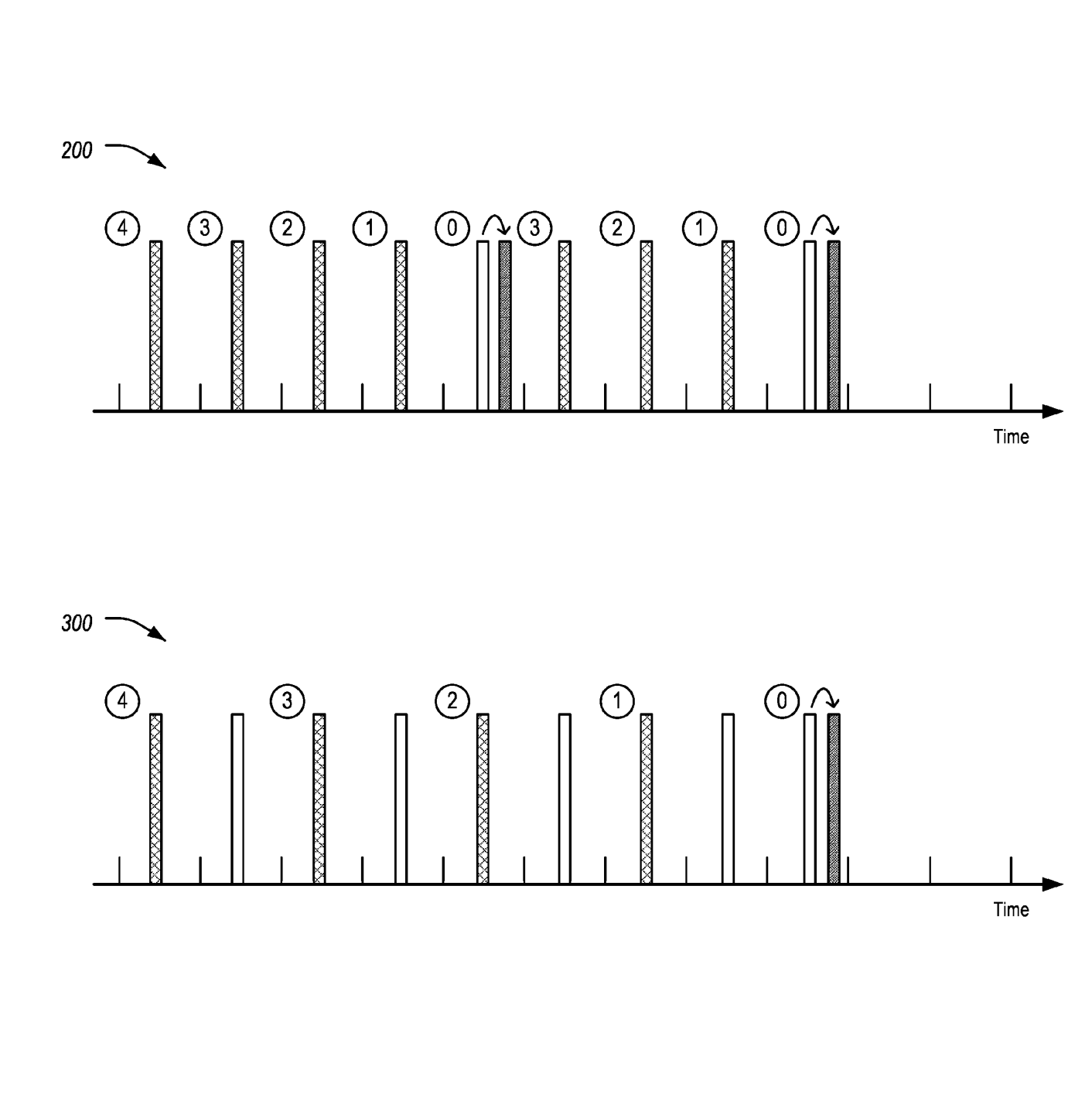
|
Jayanthi Rao, Ivan Vukovic, Yaser P Fallah, Md Saifuddin, Mahdi Zaman US 2023/0057331 A1 Details We developed a novel 1-shot transmission scheme for Semi-Persistent Scheduling (SPS) that improves the latency and reliability of connected messages, independent of SPS-allocated resources. |
Miscellanea |

|
Invited Lecture,
EEL 6938 Special Topics, Spring 2025, University of Central Florida |
|
|
Invited Lecture,
EEE 6712 Modeling and Analysis of Networked Cyber-Physical Systems, Spring 2024, University of Central Florida |
|
|
Instructor,
Spring 2023, University of Central Florida |
|
Originally stolen from Jon Barron's amazing website (source code). Feel free to repurpose. |